사용자가 특정 차트를 고르면, 전 종목의 과거(10년) 차트들을 모두 탐색하여 가장 유사한 차트 10개를 골라 사용자에게 보여줍니다.
비슷한 차트 검색기
전 종목의 최근 10년간 모든 차트를 탐색합니다. 내 종목의 차트는 과연 상승하는 차트일까요?
www.similarchart.com
KMP 알고리즘이란
KMP알고리즘은 텍스트 내(본문)에서 특정 문자열, 패턴("테이프")을 찾는 문자열 검색을 할 때 사용하는 알고리즘이다.
만든 사람이름이 Knuth, Morris, Prett이기 때문에 앞글자를 하나씩 따서 KMP알고리즘이라고 한다.
일반적으로 떠올리는 방법인 순차적 탐색보다 훨씬 효율적이다.
KMP알고리즘의 시간 복잡도는 O(N+M)으로 순차적 탐색방법 O(NM) 보다 매우 빠르다.
먼저 알아야 하는 것
KMP 알고리즘을 이해하기 위해 먼저 알아야 하는 것이 2가지가 있다.
1. 접두사와 접미사
ABCDE를 예로들면
- 접두사
- A
- AB
- ABC
- ABCD
- ABCDE
- 접미사
- E
- DE
- CDE
- BCDE
- ABCDE
2. 접두사 접미사 최장 공통 배열(kmp table)
kmp table [i]는 주어진 문자열의 0~i까지의 부분 문자열 중에서 접두사 == 접미사가 될 수 있는 부분 문자열 중에서 가장 긴 것의 길이다. (이때 prefix가 0~i까지의 부분 문자열과 같으면 안 된다.)
예를 들어 문자열 "ABAABAB"의 pi배열은 0011232이다
| i | 부분 문자열 | table[i] |
|---|---|---|
| 0 | A | 0 |
| 1 | AB | 0 |
| 2 | ABA | 1 |
| 3 | ABAA | 1 |
| 4 | ABAAB | 2 |
| 5 | ABAABA | 3 |
| 6 | ABAABAB | 2 |
KMP의 동작 방식
문자열이 불일치할 때 탐색을 시작했던 위치의 다음 문자부터가 아닌 일정 부분을 건너뛸 수 있다고 가정을 해보자.
만약 문자열 탐색을 건너 뛸 수 있다면 어떤 전제조건이 꼭 성립해야 할까?
건너뛴 후의 탐색 문자열의 앞부분과 원본 문자열의 뒷부분이 일치해야 한다 가 전제조건으로 성립해야 한다.
문자열 탐색을 일정 부분 건너뛴후 원본 문자열과 탐색 문자열을 비교한다는 것 의 의미는 건너 뛴 후 부터는 다시 원본 문자열과 탐색 문자열이 일치해야한다는 의미이다.
건너 뛴 후의 원본 문자열과 탐색 문자열이 일치해야 그 이후로 다시 탐색을 진행할 수 있기 때문이다.
반대로 일정 부분 건너뛴 후 원본 문자열과 탐색 문자열이 일치하지 않는다면, 건너뛰는 의미가 없다.
여기서 얻을 수 있는 결론은 탐색 문자열의 앞부분과 원본 문자열의 뒷부분이 동일한 부분 까지는 문자열 탐색을 건너뛸 수 있다는 사실이다.
kmp_table도 이 방식으로 똑같이 만들 수 있다.
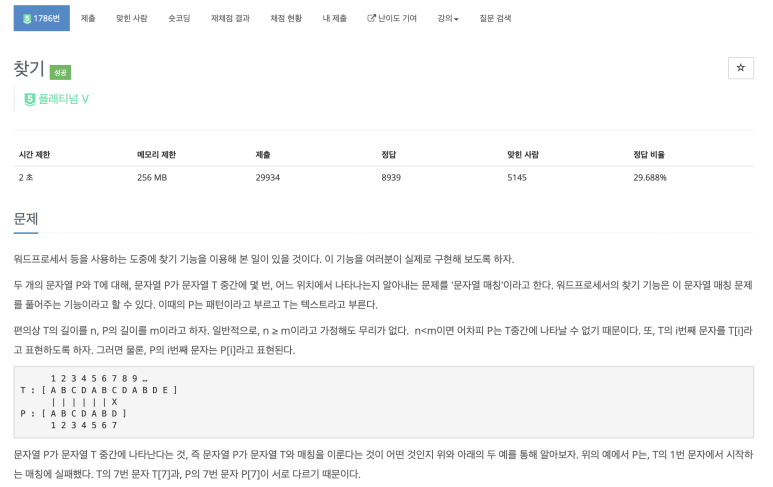
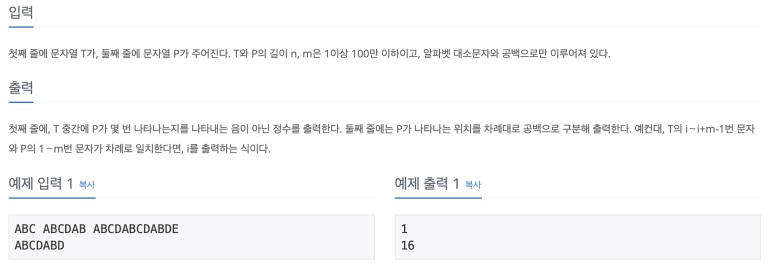
백준 1786번 문제
)

)
import sys
input = lambda : sys.stdin.readline().rstrip()
def maketable(p, kmp_table):
j = 0
for i in range(1, len(p)):
while j > 0 and p[i] != p[j]: # 다르면 바로 이전(j-1) kmp 테이블로 간다
j = kmp_table[j-1] # 가서 필요없는부분 점프한다
if p[i] == p[j]:
j += 1
kmp_table[i] = j
def kmp(t, p, kmp_table):
maketable(p, kmp_table)
j = 0
result = []
p_size = len(p)
for i in range(len(t)):
while j > 0 and t[i] != p[j]:
j = kmp_table[j-1]
if t[i] == p[j]:
if j == p_size - 1:
result.append(i - p_size + 2)
j = kmp_table[j]
else:
j += 1
return result
T = input()
P = input()
kmp_table = [0] * len(P)
ans = kmp(T, P, kmp_table)
print(kmp_table)
print(len(ans))
print(*ans)7번째 줄에
while j > 0 and p[i] != p[j]: # 다르면 바로 이전(j-1) kmp 테이블로 간다
j = kmp_table[j-1] # 가서 필요없는부분 점프한다부분이 어려울 수 있는데,
kmp table을 설명할 때 사용했던 P='ABAABAB'(table은 0011232)를 예로 들자면,
ABAABAB의 마지막문자인 B의 table 값을 구할 때는 j=3 i=6인 상태고, P [i=6] = B와 P [j=3] = A가 다르므로, table [j-1=2]를 조회한다.
table=[2] = 1이어서 P [1]과 P [6]을 비교했더니 P [1]=B == P [6]=B이다! 이것의 의미는
ABAABAB
ABAABAB 비교에서
ABAABAB
ABAABAB 로 점프한다는 의미이다! 어렵다..KMP 알고리즘은 빠르게 이해하기가 힘들었다. 5시간이 넘게 쳐다보고 이것저것 실험해 보고서야 어느 정도 이해가 됐다.
알고리즘 자체의 난이도가 플래티넘 5인 것이 이해가 된다.
'알고리즘' 카테고리의 다른 글
| 강한 연결 요소(타잔 알고리즘) - 백준 2150 (22.7.27) (0) | 2024.02.13 |
|---|---|
| 최소 공통 조상 알고리즘 - 백준 3584 / 11438 (22.7.22) (0) | 2024.02.13 |
| 벨만 포드 알고리즘 - 백준 11657 (22.7.17) (0) | 2024.02.13 |
| 투 포인터 알고리즘 - 백준 1806 (22.6.30) (1) | 2024.02.13 |
| 서로소 집합과 크루스칼 알고리즘 - 백준 1197 (22.6.29) (0) | 2024.02.13 |